CONVERGE 3.0の並列化効率の検証

皆さま、こんにちは。
IDAJの水島です。
今回は、オートノマスメッシング熱流体解析プログラム「CONVERGE」の開発元である、Convergent Scienceが公開しているBLOGの内容を翻訳してご紹介します。
競争の激しい市場では、現象の予測が可能な計算流体力学(Computational Fluid Dynamics、CFD)は、製品の設計・開発における“強み”となります。製造前に製品の問題領域を予測できるだけでなく、設計を計算で最適化して、物理モデルのテストのためのリソースを減らすことができます。
CFDを使って正確な予測を得るには、高解像度なグリッド収束メッシュ、詳細物理モデル、高次の数値計算法、ロバストな化学反応が必要ですが、これらには多大な計算コストがかかります。迅速に製品を設計するためにシミュレーションを用いても、そのシミュレーションを妥当な時間内で実行できなければ効果的とは言えません。
高性能コンピューティング(HPC)の導入によって、より短時間で正確な結果を得る能力が飛躍的に向上しました。複数コアでシミュレーションを並列実行することで、極めて長い時間がかかったであろう、何百万ものセルや複雑な物理現象のあるケースを解析することができるようになりました。
しかし、単にコア数を増やして計算実行しても、必ずしもそれが有意な高速化につながるとは限りません。HPCを用いた高速化の良し悪しは、コードの並列化アルゴリズムによって決まります。したがって、製品開発のターンアラウンドを速めるには、並列化アルゴリズムを向上させなければなりません。
基本からはじめよう
問題をパーツに分解して、これらのパーツを複数のプロセッサで同時に解析することが並列化です。理想的に並列化された問題は、コア数に反比例してスケーリングし、コア数が2倍になると実行時間が半分になります。
HPCにおける一般的なタスクは、アプリケーションのスケーリング効率とも呼ばれるスケーラビリティを測定することです。スケーラビリティは、コア数あるいはプロセッサ数の変化が、シミュレーションの実行時間に与える影響についての研究です。スケーリング傾向は、コア数に対する速度変化を把握することで可視化することができます。
CONVERGEでは並列化をどのように行うのか?
CONVERGE2.4以前における並列化
CONVERGE 2.4以前では、並列化は、解析領域をベースグリッドよりも粗い並列ブロックに分割して行っていました。CONVERGEは、ブロックをプロセッサに分配し、その後負荷分散を行います。負荷分散では、各プロセッサにほぼ同じ数のセルが割り当てられるように、並列ブロックが再分配されます。
並列ブロック手法は、シミュレーションの計算領域に高レベルの細分割(ベースグリッドより細かいメッシュに分割されている領域)が含まれていない限り、うまく機能します。これらのケースでは、単一の並列ブロックのセルを、複数のプロセッサ間で分けることができないため、並列化はうまくいきません。
下図は、CONVERGE 2.4を使った並列ブロック負荷分散のテストケースを示します。コンターの色は各プロセッサが持つセルを表します。ご覧のように、中央部の高度に細分割された領域は数個のブロックがカバーすることになり、ブロック内のセル数が多くなり過ぎています。その結果、プロセッサ全体のセル分配に偏りが生じています。この現象は、妥当な負荷分散を維持する一方で、CONVERGE 2.4で可能な細分割のレベル数に実際的な制限を課すものとなっています。

図1 CONVERGE 2.4における並列ブロック負荷分散
CONVERGE 3.0における並列化
CONVERGE 3.0では、並列ブロックを生成する代わりに、並列化はセルベース、すなわちセルごと、の負荷分散によって行われます。各セルはどのプロセッサにも属することができるため、セルの分配がかなり柔軟になり、細分割のレベルを気にする必要がなくなりました。
図2は、図1と同テストケースを用いて、CONVERGE 3.0でセルベースの負荷分散を使ったプロセッサ間のセル分配を示します。ご覧のように、並列ブロックの制限がなければ、細分化レベルの高い領域内のセルであっても多数のプロセッサに分けられ、セルがおおよそ等分配されています。

図2 CONVERGE 3.0におけるセルベース負荷分散
セルベースの負荷分散手法は、コア数が多い場合でも、スケーリングがかなり向上していることを実証するものです。前バージョンとは異なり、CONVERGE 3.0では負荷分散自体を並列で実行し、シミュレーションを加速させています。
ケーススタディ
セルベースの並列化がどの程度うまく機能するのかを確認するため、strong scalingの調査を多くのケースにおいて行いました。strong scalingという用語は、セル数や設定パラメータなどを一定にする全く同じシミュレーションを、異なるコア数で実行することを意味します。
SI8 PFI エンジンのケース
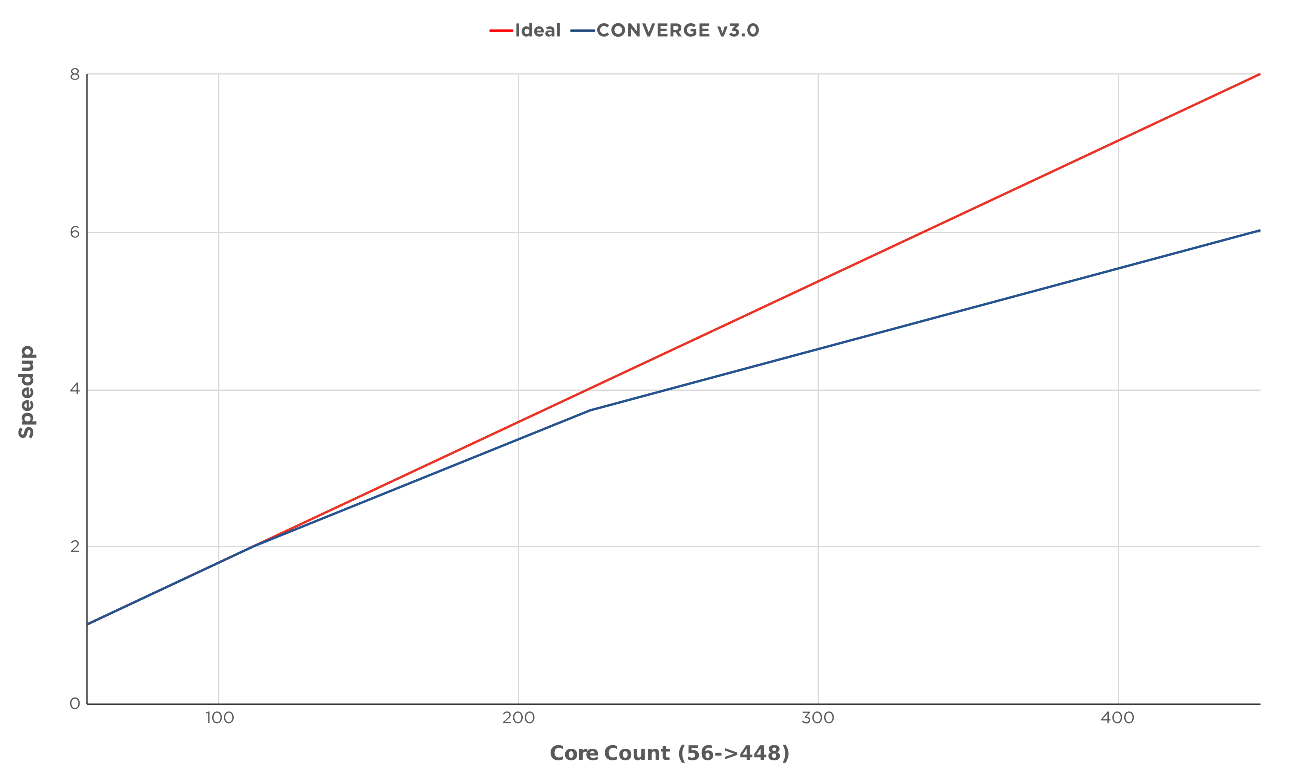
図3は、CONVERGE 3.0を用いた、標準的なSI8ポート燃料噴射(PFI)エンジンのスケーリング結果を示します。このケースでは、フルエンジンサイクルを1回実行し、コア数は56から448へと変化させています。プロットは、理想的な加速と、CONVERGE 3.0でケースを実行して得られた加速を比較したものです。十分なCPUのリソースがある場合(ここでは448コア)、詳細化学反応を使った1エンジンサイクルのシミュレーションを2時間以内で行うことができ、CONVERGE 2.4に比べて3倍の高速化を達成しました。
|
コア数 |
時間 (h) |
加速 |
効率 |
1コアあたりのセル数 |
1日あたりのエンジンサイクル |
|
56 |
11.51 |
1 |
100% |
12,500 |
2.1 |
|
112 |
5.75 |
2 |
100% |
6,200 |
4.2 |
|
224 |
3.08 |
3.74 |
93% |
3,100 |
7.8 |
|
448 |
1.91 |
6.67 |
75% |
1,600 |
12.5 |
図3 インハウスのクラスタで実行した、CONVERGE 3.0を使ったSI8 PFIエンジンシミュレーションのスケーリング結果。コア数が448個の場合は、CONVERGE 3.0では75%の効率でスケーリングを行い、1日12エンジンサイクル以上のシミュレーションを行うことができる。なお、並列化プロファイルはケースごとに異なる。
Sandia Flame Dのケース
ここからは、Sandia Flame Dのケースのスケーリング調査についてご紹介します。
図4に、Sandia Flame Dのケースについて行われたstrong scaling調査の結果を示します。ここでは、1億7千万個のセルを使ってメタン火炎ジェットのシミュレーションを行いました。計算は、米国立スーパーコンピュータ応用研究所(National Center for Supercomputing Applications :NCSA)のBlue Watersスーパーコンピュータで実行し、コア数は500から8,000へと変化させています。CONVERGE 3.0は、コア数が何千とある場合でも、見事にほぼ線形のスケーリングが行われることを実証しています。
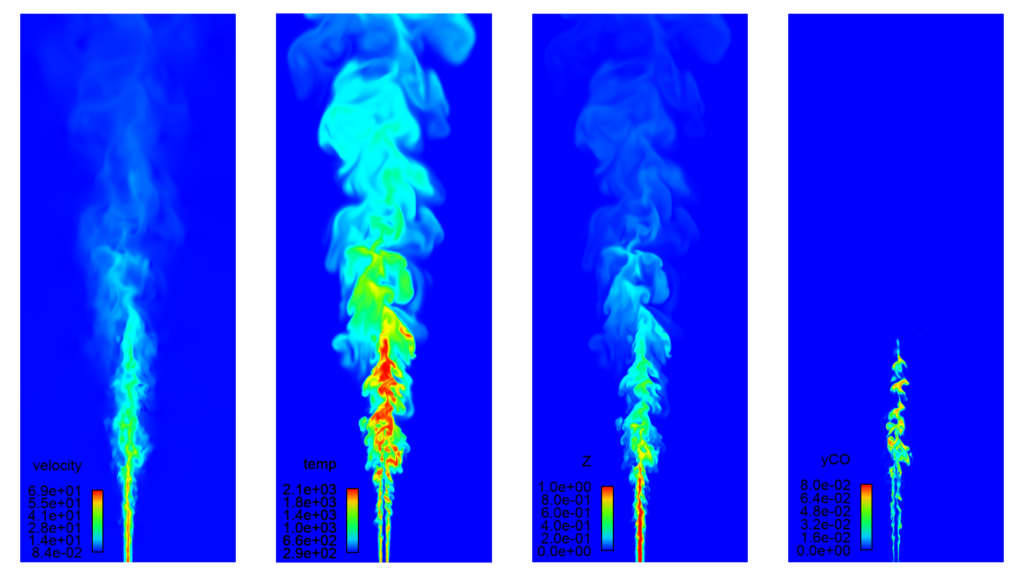
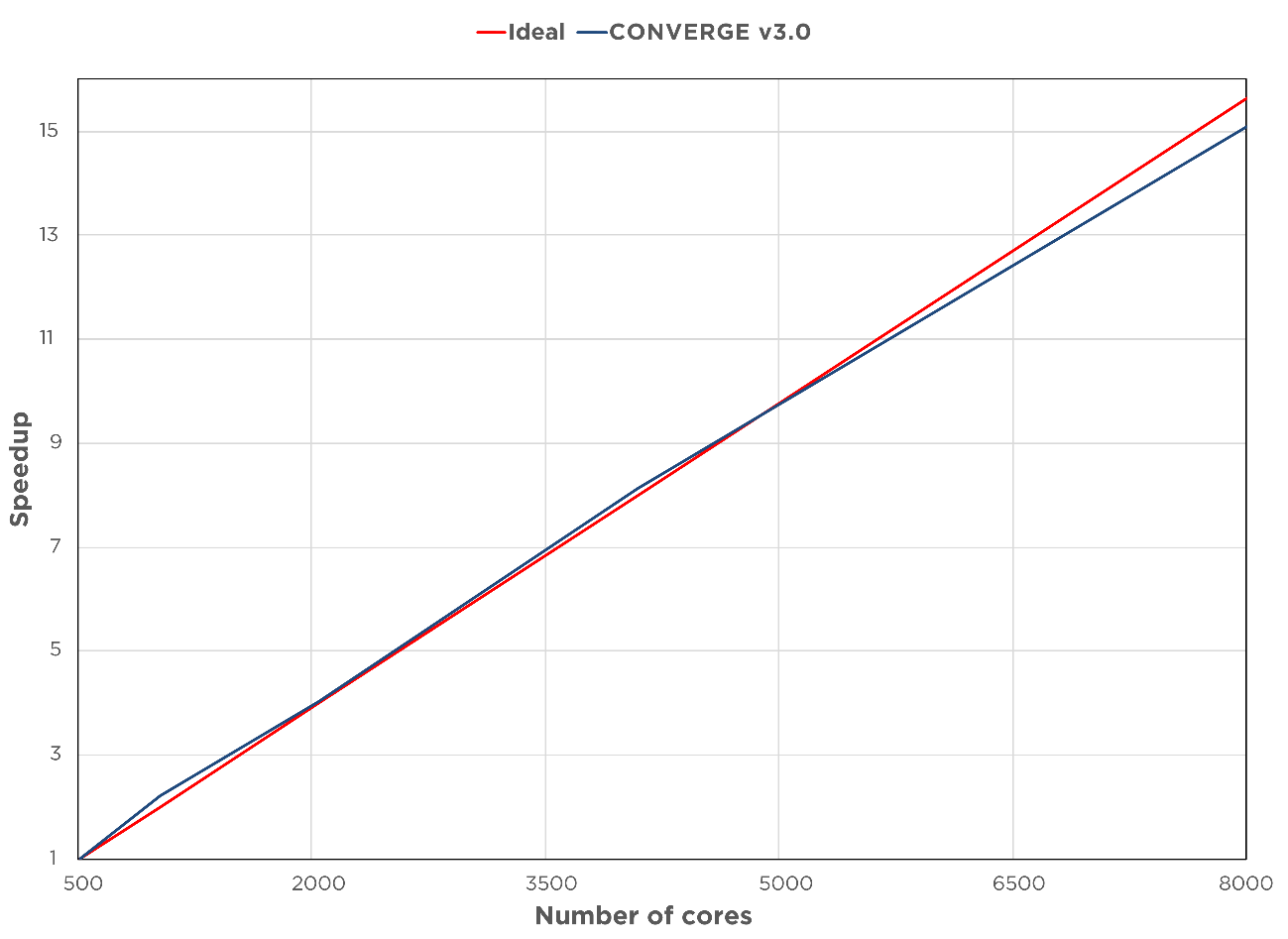
図4 米国立スーパーコンピュータ応用研究所のBlue Watersスーパーコンピュータで実行された、部分予混合燃焼された燃焼乱流(Sandia Flame D)の、CONVERGE 3.0でのスケーリング結果[1]。コア数8,000で、CONVERGE 3.0のスケーリング効率は95%を達成。
結論
これまでのバージョンでも、コア数が増えた場合には着実に実行時間は改善されましたが、局所細分割の多いケースでは、加速には限りがありました。CONVERGE 3.0は、1ノードあたりのコア数が多い現代のハードウェア構成で、効率よく実行されるよう開発されています。
CONVERGE 3.0では、1コアにつき1,500セルほどしかないシミュレーションでも、加速が増加することを確認しています。スケーリング効率が向上したこの新しいバージョンでは、巨大なケースでもシミュレーション結果を迅速に得ることができるため、製品を市場に出すのにかかる時間を減らすことができます。
CONVERGE 3.0でシミュレーションを加速させる方法につきましては、IDAJまでお気軽にお問い合わせください。
[1] イリノイ大学アーバナ・シャンペーン校の米国立スーパーコンピュータ応用研究所(National Center for Supercomputing Applications:NCSA)は、国の科学事業向けにスーパーコンピュータによる計算と高度なデジタルリソースを提供している。NCSAでは、イリノイ大学の教授陣、スタッフ、学生、世界中の共同研究者が高度なデジタルリソースを用いて、科学と社会のため、壮大な問題に取り組んでいる。NCSA Industry Programは、世界最大の産業HPC活動であり、30年以上にわたって、産業、研究者、学生を集めて壮大な計算問題を急速、大規模に解くことで、Fortune 50®の3分の1の企業の発展に貢献。CONVERGEのシミュレーションは、大学キャンパス内で最も高速なスーパーコンピュータの1つ、NCSAのBlue Watersスーパーコンピュータで実行された。Blue Watersは、ACI-0725070 および ACI-1238993によってアメリカ国立科学財団(National Science Foundation:NSF)の支援を受けている。
出典:CONVERGENT SCIENCE BLOG(2020年8月14日公開)
(一部編集して翻訳)LEVELING UP SCALING WITH CONVERGE 3.0

アプリケーションエンジニア Sankalp Lal
CONVERGEをご存じでない皆様、是非こちらをご視聴ください。CONVERGEの概要について9分で確認いただけます。
CONVEREGEの適用についてご不明な点がございましたら、お気軽に弊社までお問い合わせください。

■オンラインセミナー(無料)のご紹介
「CONVERGE」ご紹介セミナー ~3次元流体解析の新たな可能性を~
オートノマスメッシング熱流体解析プログラムCONVERGEは、2008年の販売を開始以来、エンジン筒内の3次元解析をメインターゲットに、世界中で広くご活用いただいています。
普段CONVERGEをご利用いただいていないモデルベース開発を統括・推進されていらっしゃる開発責任者・管理職・シニアエンジニアの皆様、これからCONVERGEのご導入をご検討される方、IDAJにコンサルティング業務の依頼を検討される方に、CONVERGEがどういう場面でお役立ていただけるかをわかりやすくご紹介しています。
セミナーの詳細・お申し込みはこちら
■オンラインでの技術相談、お打合せ、技術サポートなどを承っています。
本件ならびに本記事で登場する製品やサービスに関しては、下記までお気軽にお問い合わせください。ご連絡をお待ちしています。
株式会社 IDAJ 営業部
Webからのお問い合わせはこちら
E-mail:info@idaj.co.jp
TEL: 045-683-1990