AI時代に求められる次世代半導体パッケージ:シミュレーションが導く熱設計の最適解(その1)

皆さま、こんにちは。
IDAJの錦織です。
ここ数年で生成AIは一気に身近な話題になりました。検索や文章作成だけでなく、設計・開発の現場でも「まずAIに聞いてみる」、「試しに生成して比べてみる」といった使い方を見かける機会も増えました。こうした流れの裏側では、学習・推論を支える計算量とデータ量が跳ね上がり、処理基盤にはこれまで以上の性能が求められるようになっています。
この要求はクラウドだけの話ではありません。パソコンやエッジ機器、産業機器に加えて、自動車分野ではADAS(先進運転支援システム)の高度化や統合ECUの発展によって、高速な並列計算や大容量データの処理がより現実的な課題になっています。結果的に、演算を担う半導体は高性能化し、それを支えるパッケージは、チップレット(2.5D・3D積層など)、HBM(High Bandwidth Memory)といった“高集積”の方向へと進んでいます。
一方で、この高集積化は熱の面で新たな“難しさ”を生じさせることにもなっています。発熱密度が上がって熱が逃げにくくなることに加えて、積層・近接実装によって熱干渉(Thermal Crosstalk)が起きやすくなり、放熱経路が複雑化しています。その結果、試作だけで最適解を探すことが難しくなるケースも少なくありません。
そこで本記事では、生成AIやADAS、車載統合ECUで利用が進む次世代半導体パッケージを題材に、「なぜ熱設計が難しくなるのか」を整理した上で、「現実的にどのように対処・最適化していくか」についてご説明したいと思います。
1. 次世代半導体パッケージとは
(1)パッケージの進化は“高密度化の歴史” そのもの
半導体パッケージは、DIPのようなシンプルな構造から始まり、表面実装、BGA、Flip Chip、SiP、そして近年のチップレット(2.5D・3Dなど)へと進化しています。ここで大事なのは、配線を短くし、帯域を増やし、密度を上げるという進化の方向性が一貫している点です。つまり、性能を上げるほど、パッケージが「立体化」するのは自然な流れだと言えます。
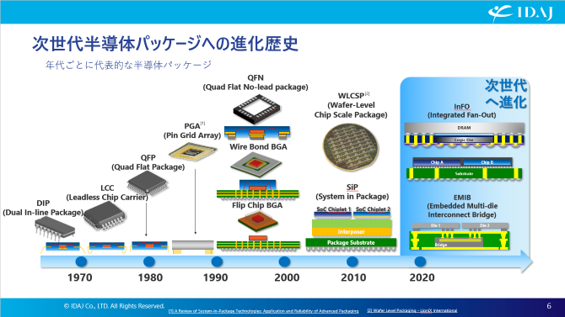
図1 半導体パッケージの進化の歴史
(2)「個別チップ」から「チップレット・積層」へ
従来は、CPU・GPU・DRAMなどがおおよそ独立して基板上に並び、配線でつながっていました(図2左)。ただ、この方式では配線長が伸びやすく、遅延や電力、帯域に限界があります。
そこでチップレットを組み合わせ、インターポーザ上で接続する2.5Dや垂直方向に積層する3Dによって、短い距離で高速に接続する構造へと移行しています(図2右)。
HBMのようにメモリを積層してGPU近傍に置く構造は、その典型例です。
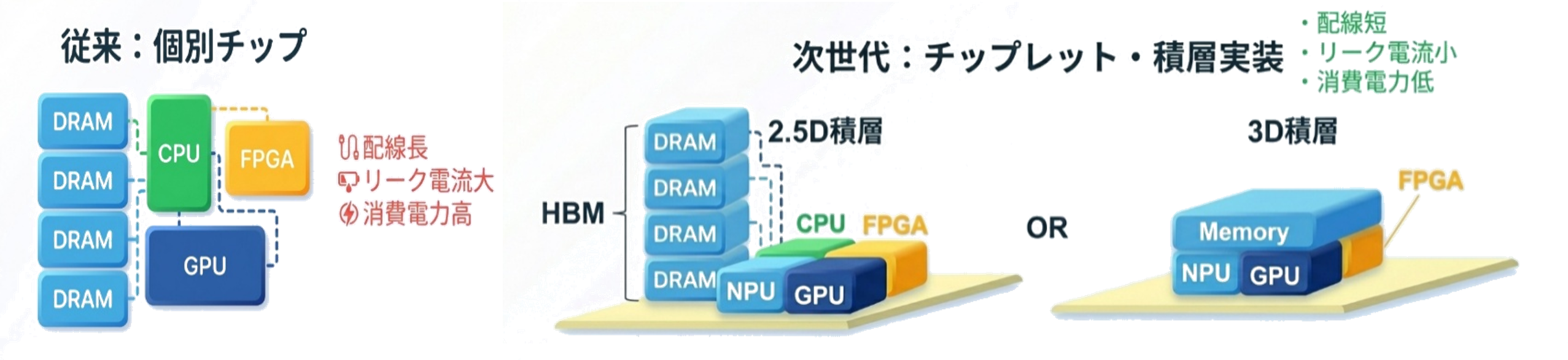
図2 従来・次世代の半導体パッケージレイアウト
2. なぜ今、次世代半導体パッケージなのか
(1)ADASが押し上げる「車載統合ECU」の処理能力
近年の車両では、従来の制御機能に加えて高度なセンシングとリアルタイム処理が必須です。これに伴ってADASが進化すると、カメラ・レーダ・LiDARなどの入力が増え、判断や制御が複雑化するため、結果として車載統合ECUにはより高い並列計算能力が求められます。
機能ごとに分かれていたECUが統合されるほど、「計算が一箇所に集まる」ため、発熱も“集まって”しまいます。
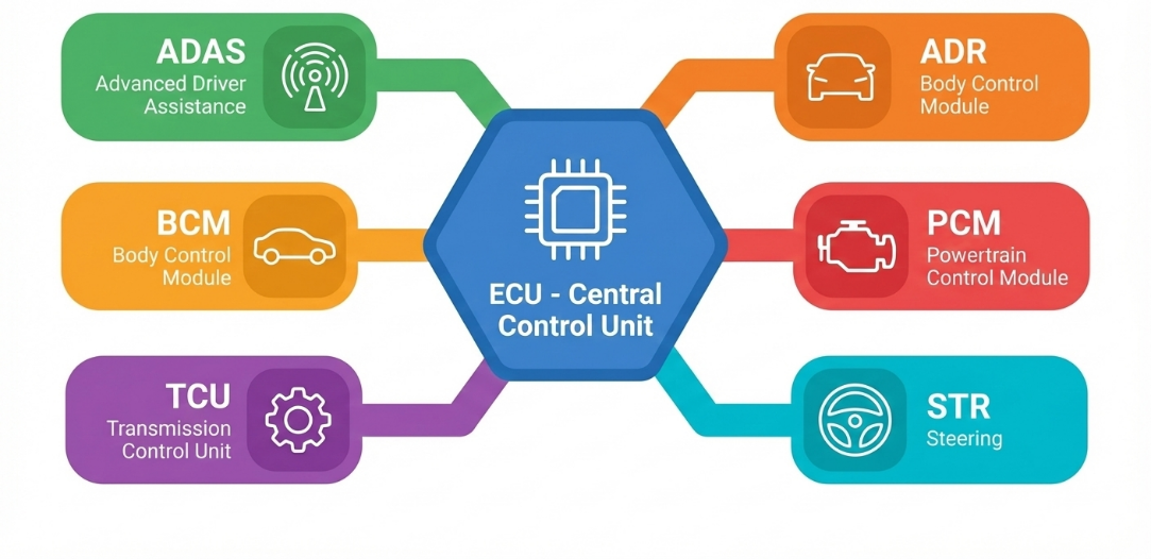
図3 統合ECUの構成
(2)生成AIが押し上げる「GPU+広帯域メモリ」の需要
生成AIでは、学習・推論・再学習のどのフェーズでも大規模な計算が必要となりますので、GPUの需要は増加の一途をたどっています。クラウド側だけでなく、ローカル側でもAI処理が増えるほど、高性能GPUを支えるパッケージの重要度は上がります。
この中で注目されているのが、GPUと広帯域メモリを近接・高密度に接続する構成です。GPUの周りにHBMを配置し、インターポーザなどを介して広帯域通信を実現する構成がその代表例です(図4)。
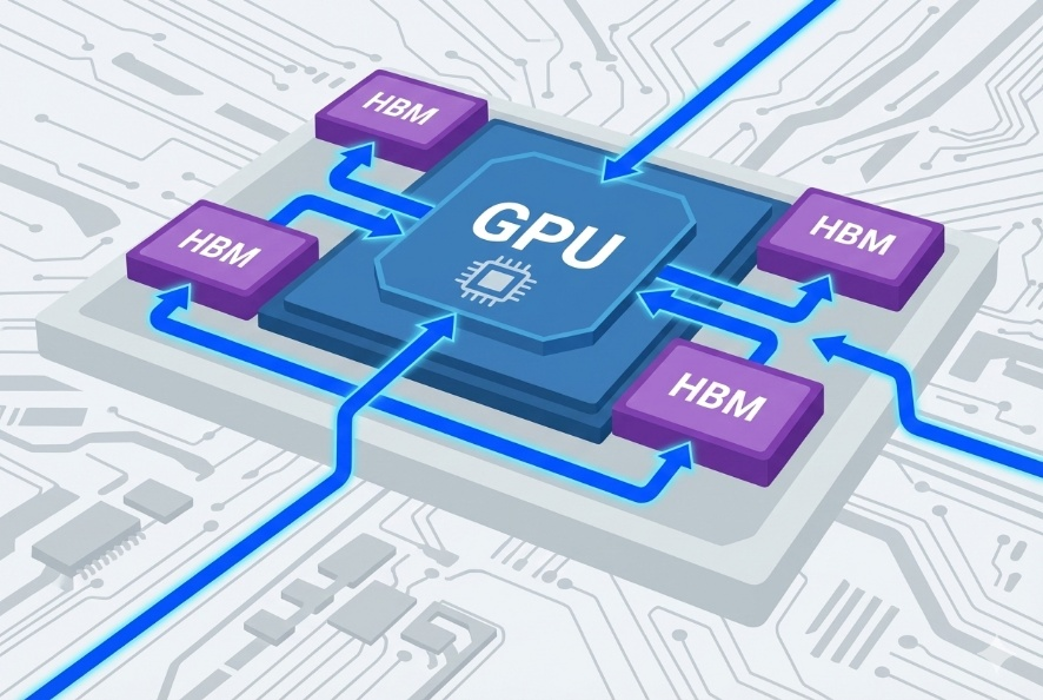
図4 HBMを搭載したGPUイメージ
3. 次世代パッケージの熱設計が難しくなる理由
(1)高性能化=「発熱密度」が増える
CPUやGPUは年々高性能化し、コア数や処理能力が伸びています。ここでよく起きるのが、消費電力そのものよりも局所的な発熱密度が上がる現象です。
熱の逃げ道が追いつかないと、スロットリングによる性能低下や、長期信頼性への毀損につながる可能性があります。さらに、積層構造になると層間で熱が干渉しやすくなる、いわゆるThermal Crosstalk(熱干渉)が設計課題として出てきます。
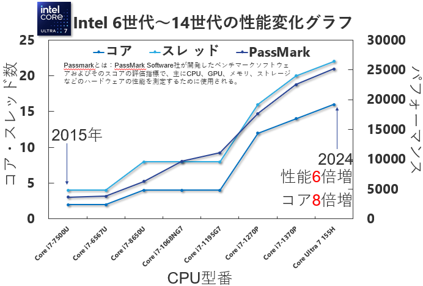
図5 Intel CPUのパッケージ設計の密集化の進化
(2)放熱経路が多いほど「全体最適」が難しい
次世代パッケージは、放熱が一方向ではありません。上方向にはヒートシンク、ファン、TIM、下方向にはPCBを通じた拡散、内部ではTSVやバンプ、材料構成が効いてきます。つまり、改善のレバーが増える分だけ、「どこを調整すれば、どこに効くのか」が直感だけではつかみづらくなります。つまり、熱が“複数の経路”と“複数の要因”で動くようになることが本質的な難しさです。
ここではポイントを3つに絞って整理します。
| ポイント①:温度が上がるだけではなく熱が「干渉」する ⇒ 積層は“近い”ため、熱が隣に影響しやすい |
高密度化した構造では、あるチップの熱が周辺のチップへ伝わりやすく、温度分布が単純ではありません。特定の層や領域に熱が溜まり、ホットスポットができ、周辺チップの温度も引き上げてしまいます。
この“干渉”が厄介なのは、個別部品の放熱対策だけでは解決しづらい点です。チップ間距離、材料、接合、TSVやバンプなどの配置密度、構造パラメータなどが絡み合って効いてきます。結果として、経験則だけで判断しづらくなるのです。
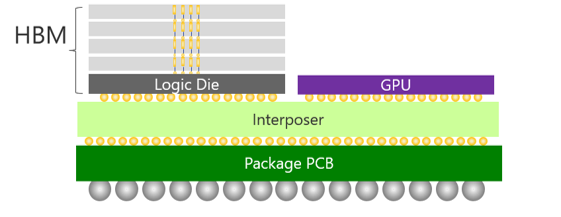
図6 HBMを搭載したGPUレイアウト設計例
| ポイント②:性能は伸びるのに、熱設計の“余裕”は増えない ⇒ 高性能化=局所発熱の増加で、後工程では熱設計を成立させにくくなる |
CPU・GPUは急速に進化し、コア数や処理能力は伸び続けています。しかし設計として、「熱的な余裕」が同じ速度で増えるわけではありません。放っておけばスロットリングのような性能低下や、信頼性の面でのリスクにつながります。特に車載領域のように長期信頼性が重視される領域では、ピーク温度だけでなく温度勾配や熱サイクルまでを含めて検討する必要があり、熱設計は“後から何とかする”が通用しなくなっています。
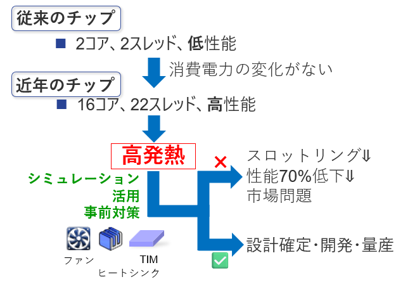
図7 熱対策の必要性
| ポイント③:放熱経路が多く、詳細な検討が複雑 ⇒ 熱の逃げ道が増えるほど、“どこを変えると何が動くか”が掴みにくくなる |
次世代パッケージでは、上側のヒートシンク、ファン、TIMだけでなく、下側のPCB(銅面積、サーマルビア、グラウンドプレーン、材料)も影響します。さらにパッケージ内部でも、チップ間距離、TSVやSolder、封止材やアンダーフィルなど、影響因子が非常に多くなります。
以下はノートパソコンを例とした内部の放熱構造ですが、「どこを調整すると、どの温度がどれだけ変わるか」を把握するだけでも一苦労です。試作で全てを確認することは現実的ではありませんし、簡略化しすぎると熱干渉のような現象を見落としやすくなります。ここに、次世代パッケージ熱設計の難しさが詰まっているのです。
●ルートA:上側のヒートシンク、ファン、TIM
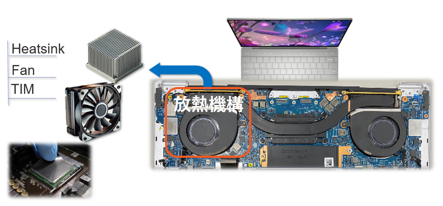
図8 サーマルモジュールからの放熱ルート
●ルートB:パッケージ内部のチップ間距離、TSV、Solder、封止材やアンダーフィルなど
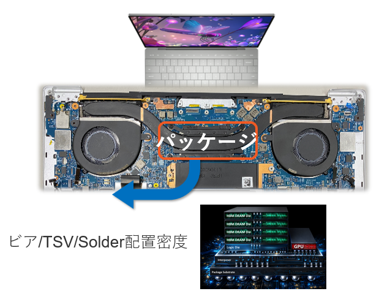
図9 半導体パッケージ内部の放熱ルート
●ルートC:下側のPCB(銅面積、サーマルビア、グラウンドプレーン、材料)
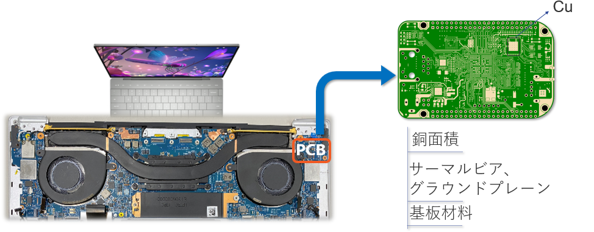
図10 プリント基板からの放熱ルート
4. ここまでのまとめ
- 自動運転や生成AIの進化によって、処理能力だけでなく帯域(データ転送)が重要になり、次世代パッケージの必要性が高まっています。
- 次世代パッケージの中心は、チップレット(2.5D/3D積層)、HBMなどの“つなぎ方”を変える構造への進化です。
- 一方で、積層・高密度化は熱密度の増大+Thermal Crosstalk+多経路放熱の原因となり、熱設計の難易度を一段と引き上げます。
次回は、この複雑さに対して「どう設計を進めるのが現実的か」、試作だけに頼らず 早い段階から熱シミュレーションで当たりをつける観点からご説明できればと思います。パッケージ側の微調整だけでなく、ヒートシンクやファン、PCBといった設置環境を含めた手法、シミュレーションを活用した熱設計事例をもう少し具体的にご紹介します。

■オンラインでの技術相談、お打合せ、技術サポートなどを承っています。下記までお気軽にお問い合わせください。ご連絡をお待ちしています。
株式会社 IDAJ 営業部
Webからのお問い合わせはこちら
E-mail:info@idaj.co.jp
TEL: 045-683-1990