CAEとディープ・ラーニング(前編)

皆さま、こんにちは。
IDAJの清水です。
昨今のディープ・ラーニングによる技術的ブレーク・スルーによって、いわゆるヒューマン・ライクな処理をコンピュータが自動的に行うAI(Artificial Intelligence:人工知能)の利用が現実的なものとなりました。
画像判別、音声認識、翻訳などでは、すでに多くのサービスがディープ・ラーニングによるAIによって提供されています。
AIと機械学習と深層学習
AIは、人手不足の救世主として扱われることもあれば、「○○年には現在の仕事の○割がAIに取って代わられる!」というショッキングなフレーズで、蛇蝎のごとく嫌われるシーンを目にすることもあります。ですが、すでに私たちも、身近なところでAIの恩恵にあずかっています。パソコンやスマホの日本語入力では、前後の言葉やその使用頻度を勘案して文字を変換してくれるというのもAIのアプリケーションの一つです。また、「○○という質問についてはAIがお応え」という仕組みも目にするようになりました。しかし実は、「○○という質問が来たら△△と回答せよ」とシステム化されているだけということもあります。それでもAIと呼ばれ、とても広範囲に用いられているようです。AIとは、いったいなんでしょうか?辞書や人工知能学会、その他の情報を見ていても、どうやら現在のところは、厳密な定義はなされていないようです。
AIは、実際には古くて新しい言葉です。第1次ブームは1956年〜1960年代、第2次ブームは1980年代だと言われています。そして現在のブームは2010年頃から始まりました。この背景には、ビッグデータの普及、ディープ・ラーニングの発見、人工知能の影響力や脅威の伝達などといった、これまでの科学の発展があげられます。
私が初めて「AI」を明確に意識したのは、2001年に公開されたアメリカの映画「A.I.」でした。故スタンリー・キューブリック氏が長年温めてきた企画をスティーヴン・スピルバーグ監督が映画化した、SFヒューマンドラマです。当時は、人間と同じようなロボットがAIなのか?、その心(思考?)がAIなのか?、人間に都合よくプログラミングされ、廃棄されることになった主人公がかわいそうで悲しい・・・そんな感想しか持ちませんでしたが。それから18年が経ち、この3度目のブームをエンジニアとして経験し、CAEの世界における、ディープ・ラーニングの利用への期待が日増しに高まっているのを実感しています。
話しを戻しまして、AIと機械学習(Machine Leaning:マシン・ラーニング)と深層学習(Deep Learning:ディープ・ラーニング)という言葉も関係性がわからず、少々ややこしくないでしょうか?
まずは、三者について簡単にご紹介します。
機械学習はAIの一部で、深層学習は機械学習の一部です。
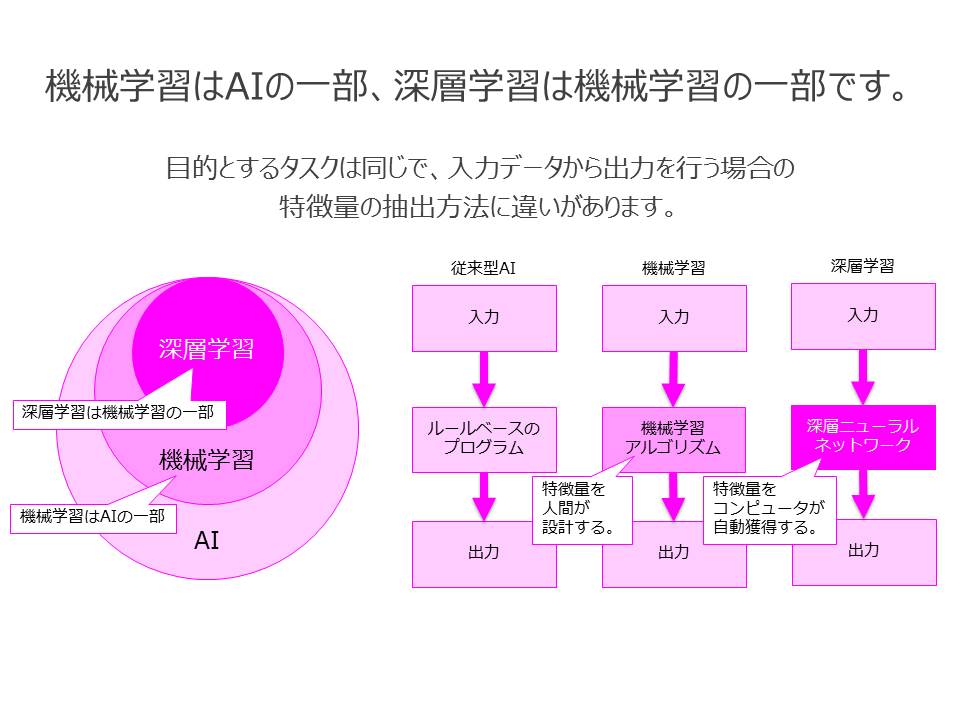
機械学習は、コンピュータが自動で処理を行うために多変量解析から発展した手法群で、最近使われる技術の中で最もポピュラーなものです。大量のデータに対して、統計的な分析やシミュレーションを組み合わせることで、対象となる物事をコンピュータが自動的に分析・予測できるようになります。人間のように自由に、または突発的にアイディアが湧いてくるわけではなく、あるミッションを持たせて膨大なデータを学習させることで、次に起こる可能性が高い事象を予測することが得意ですので、マーケティングの分野においての活用が盛んですね。「売上拡大」という目標を持たせると、顧客単価や顧客満足度の向上、アクティブユーザーの増加といったいくつかの戦術のうちの何が成功要因となりうるのかを予測して提示してくれます。
ただ、あくまでも「統計的な分析」ですので、物事を理解するわけではありません。データで表現されている数値の推移の予測や文字列、または画像を分類して構造を把握します。人間では理解できない数の評価軸を設定して、今まで隠れていた関連性を見出すことができます。しかし、複数の変数に関わりがある相関を示すことはできますが、「因果」までは証明することができませんので、これは人間の仕事です。
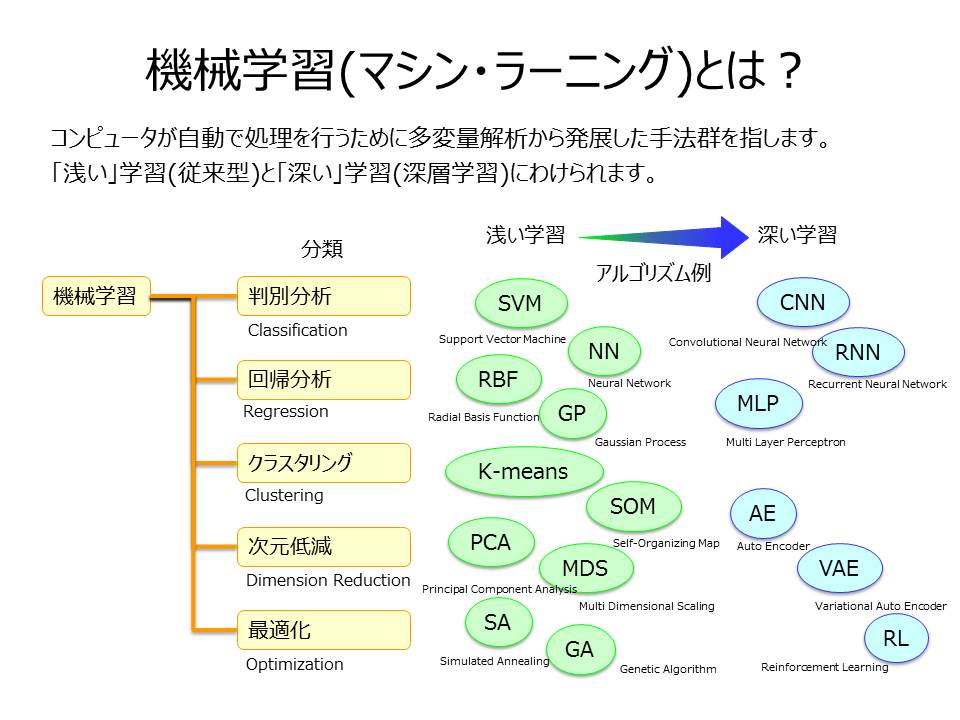
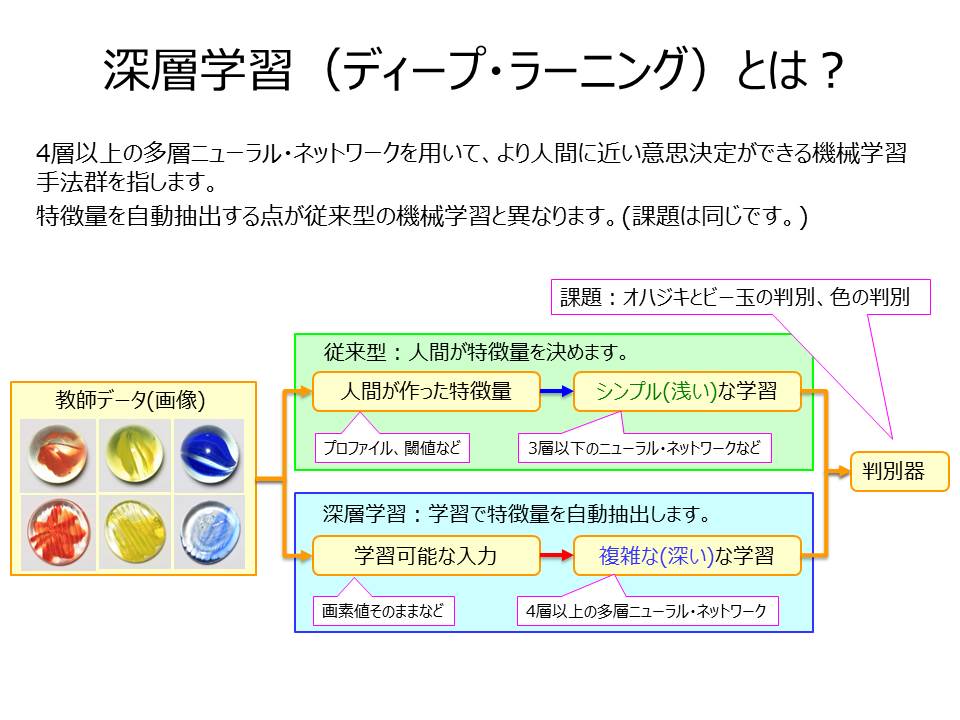
機械学習の場合は、特徴量(学習の入力に使う測定可能な特性)を人間が設計しますが、深層学習では、特徴量をコンピュータが自動獲得するという違いがあります。また、機械学習は、「浅い」学習(従来型)と「深い」学習(深層学習)とにわかれます。
浅い学習の場合は、特徴量(学習の入力に使う測定可能な特性)を人間が設計しますが、深層学習では、4層以上の多層ニューラル・ネットワークを用いて、特徴量をコンピュータが自動獲得するという違いがあります。
CAEにおけるディープ・ラーニングの利用
通常のディープ・ラーニングでは、取り扱うデータは自然界由来のデータが主体です。それに対して、CAEにおけるディープ・ラーニングで取り扱うデータは、シミュレーションによって生成されるデータが主体となります。
CAEのデータには、いくつかの特徴があります。
自然界由来のデータは、後からデータを追加することが困難ですが、CAEでは計算行うことで、後からデータを追加することは比較的容易です。また、入力データが同一であれば常に同じ結果データとなり、ノイズがありません。CAEによるディープ・ラーニングでは、このような特徴に留意する必要があります。
次回は、CAEを用いた最適設計についてご説明します。(後編はこちらです。)
➡【関連資料ダウンロード】誰でも実践できる! 踏み出そう、第一歩! modeFRONTIERを使ったノーコードデータサイエンス
追記・更新:2022年8月29日
■お問い合わせ先
株式会社 IDAJ 営業部
Webからのお問い合わせはこちら
E-mail:info@idaj.co.jp
TEL: 045-683-1990