誰でも実践できる!踏み出そう、第一歩!modeFRONTIERを使ったノーコードデータサイエンス(その1)

皆さま、こんにちは。
IDAJの清水です。
普段、最適化技術のエンジニアとしてお客様のご業務をご支援させていただく中で、最近特に、機械学習をはじめとするデータサイエンス技術とCAEでのシミュレーションを組み合わせた技術の注目度の高さを実感しています。
データサイエンスとは、統計学、情報工学、AI技術などを活用することで、膨大なデータから有益な知見や価値のある情報を引き出し、社会における様々な問題・課題を解決することを指します。インターネットの普及などの社会的背景や、センサー技術の進化によるデータの多様化、クラウドコンピューティングによるデータ管理の向上などのIT技術の進化によりビッグデータを有効に使えるようになったことで、データサイエンスへの注目度は増々高まっています。多くの企業ではデータサイエンス、AI、DX(デジタルトランスフォーメーション)といったキーワードで、意思決定の迅速化、業務の自動化・効率化、自社商品・サービスの改善といった様々な業務改革を進めています。
2021年には経済産業省をオブザーバーとして、データサイエンティスト協会、一般社団法人日本ディープラーニング協会、独立行政法人情報処理推進機構(IPA)の3団体が参加するデジタルリテラシー協議会が設立されました。「Society 5.0」が示すより良い社会創出に向け、デジタルを使う人材の育成を目的に、IT・ソフトウェア領域、数理・データサイエンス領域、人工知能・ディープラーニング領域を合わせた共通リテラシー「Di-Lite」の推進を発表しています。このようにデータサイエンス、AIは技術の進化、普及の動きが急加速している状況にあります。
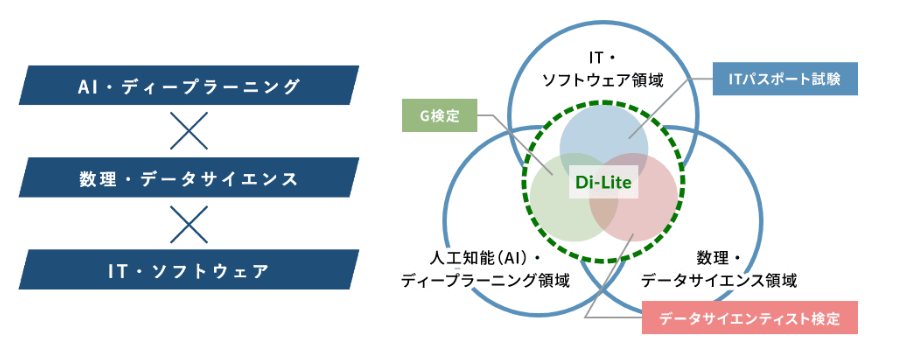
Di-Liteにおける技術領域
参考:デジタルリテラシー協議会 https://www.dilite.jp/#sect07
一方で、データサイエンスやAIの活用を躊躇される方が少なからずいらっしゃることも事実だと思います。その原因の一つには、RやPythonなどのプログラミングスキルの習得の難しさにあるのではないでしょうか。データサイエンスやAIに関する記事や参考書の多くで、RやPythonなどを用いた分析事例をよく見かけますが、データサイエンスの目的は「データから価値を引き出し、ビジネス課題を解決すること」にあり、そのための手段は個々人が使いやすい手法やツールを使えばよいと個人的に考えています。RやPythonを用いた分析は、所詮、手段の一つに過ぎません。
今回は、筆者のような思いを抱いている方々にぜひともデータサイエンスへの一歩を踏み出していただくべく、弊社で取り扱っているmodeFRONTIERを使ったNoCodeデータサイエンスについてご紹介したいと思います。データサイエンスが取り扱う対象は広く、残念ながら、すべての領域をNoCodeかつmodeFRONTIERでカバーすることはできませんが、それでもデータ分析領域においては、多くの課題解決につながる分析が可能だと考えています。データ分析業務が本職ではない設計担当者や実験担当者など、多くの方にデータサイエンスを実践いただけるような、またはそのきっかけになるような情報がお届けできればと思いますので、どうぞ最後までお付き合いください。
データサイエンスとは
冒頭でご紹介した通り、データサイエンスとは「膨大なデータから有益な知見や価値のある情報を引き出し、社会における様々な問題・課題を解決すること」です。これをデータサイエンスプロセスの観点でみると、以下に示した3つの技術領域・スキルに分けることができます。
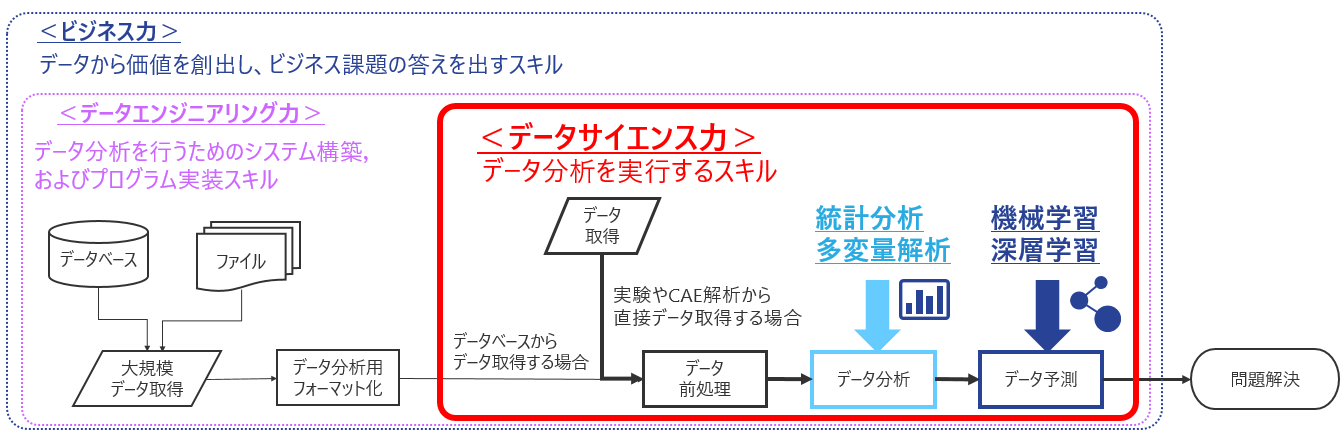
データサイエンスにおける3つの技術領域・スキル
一般社団法人データサイエンティスト協会によると、データサイエンスに求められる能力は「データエンジニアリング力」、「データサイエンス力」、「ビジネス力」の3つだとされています。
- ビジネス力:課題背景を理解したうえでビジネス課題を整理し解決する力
- データエンジニアリング力:データサイエンスを意味ある形に使えるようにし、実装・運用できるようにする力
- データサイエンス力:情報処理、人工知能、統計学などの情報処理系の知恵を理解し使う
(参考:一般社団法人 データサイエンティスト協会)
データサイエンスではこれら3つのスキルを使って、ビジネス課題を解決することを目指します。
ここからは、お客様から弊社へのお問い合わせが最も多く、また関心度が高いと思われるデータサイエンス力領域にフォーカスしてご紹介していきます。
データサイエンス力領域のプロセス
こちらは、データサイエンス力領域の基本的なプロセスです。データサイエンスに関しては、統計分析や多変量解析、機械学習(AI)などの話題がよく取り上げられます。もちろんこれらの技術を理解して活用することは大切なことですが、これらと同じくらい重要なプロセスがデータ収集とデータ前処理(データクレンジング)です。多くの専門書ではデータ分析業務の8割を占めると言われており、目的に適ったデータを取集し、適切な分析結果が得られるようデータを準備することは必要不可欠かつ重要な工程です。
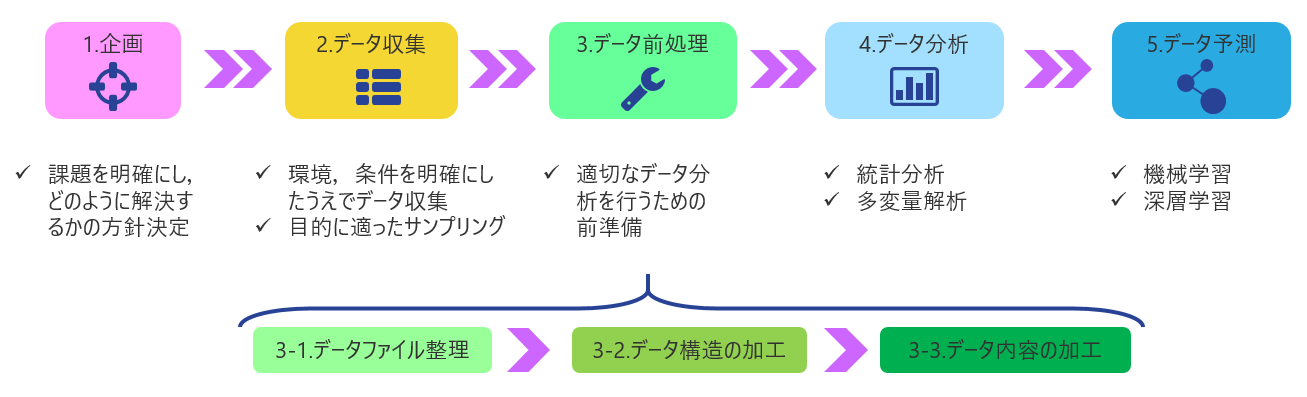
データサイエンス力領域のプロセス
1.企画
企画では、目的と課題を明確にし、どのようなプロセスで問題解決するか、またそのために取り扱うべきデータを検討します。
自動車開発をはじめとする製造業において脚光を浴びているモデルベース開発(MBD)を例に挙げますと、MBDでは市場要求から性能目標へ落とし込み、その性能目標を実現するために必要な機能を洗い出し、さらにはその機能を具現化するための要素を検討することで、各レイヤーで取り扱うインプット、アウトプットを明確にしていきます。データサイエンスにおいてもこのMBDアプローチのように、データ収集の前に目的や課題から指標を数値化し、取り扱うべきインプットとアウトプットを決定します。
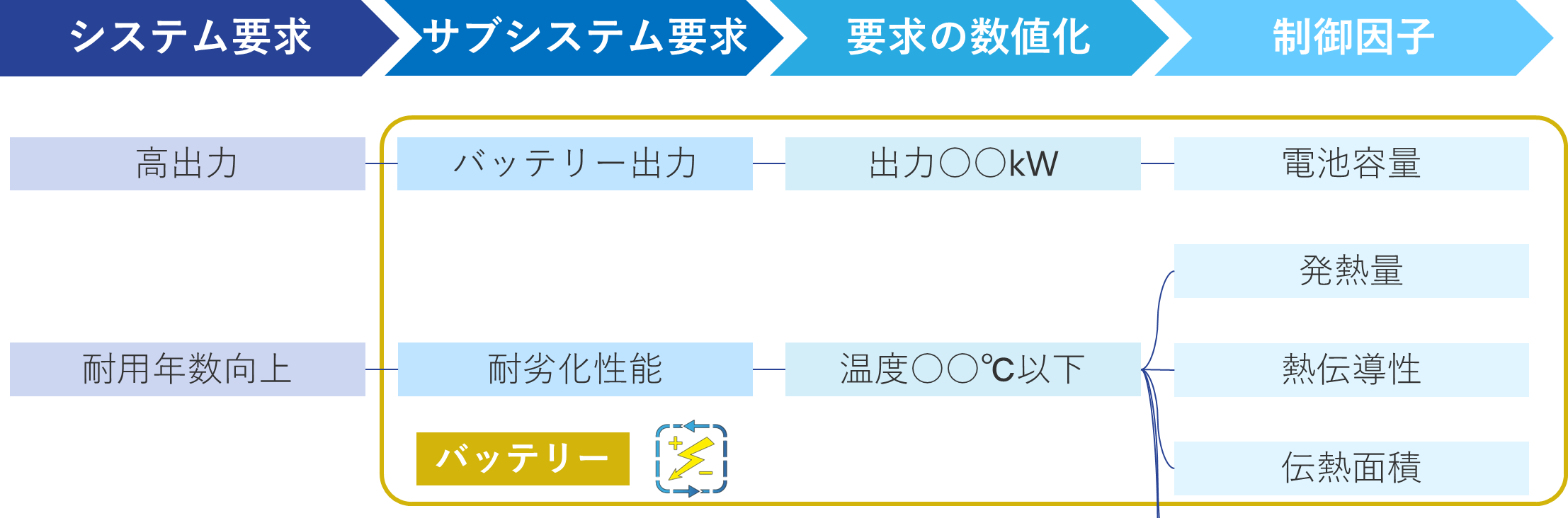
MBD(バッテリー開発)におけるインプット、アウトプットの明確化例
2.データ収集
データ収集で最も重要な要素の一つは目的に適ったサンプリングを行うことです。
|
・相関分析、寄与度分析などのデータ分析、予測モデルの構築 ⇒ ランダムサンプリング ・少ないデータ数で傾向把握 ⇒ 直交表、直交配置実験 etc. |
データ分析や予測モデルを作成する場合、もし偏ったサンプリングのデータを取得してしまうと、そのデータを使った分析や予測モデルも偏った結果となってしまうため、適切な結果が得られません。適切なデータ分析結果を得るためには適切なデータ収集が欠かせません。
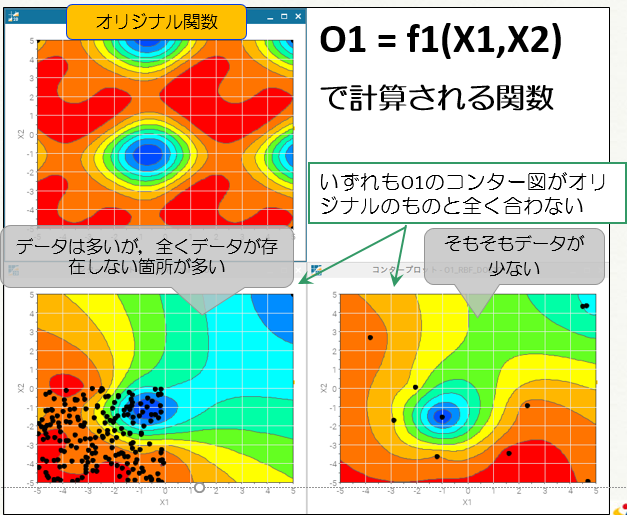
予測モデルの構築におけるサンプリング失敗例
3.データ前処理(データクレンジング)
データ前処理では適切なデータ分析を行うためのデータ加工を行います。データ加工は、およそデータ構造の加工とデータ内容の加工に分けられます。
(1)データ構造の加工
通常、取得した生データには不要なデータが混在していたり、適切なデータ構造になっていないことがあります。そこで以下のような処理を行い、分析対象とするデータ構造を整理します。
- 抽出:条件に合致するデータの抽出、間引き
- 集約:合計値、平均値、極値、代表値、標準偏差・分散の算出
- 結合:行方向の結合(過去データなど)
- 分割:条件別にテーブル分割、学習データと検証データの分割(クロスバリデーション)
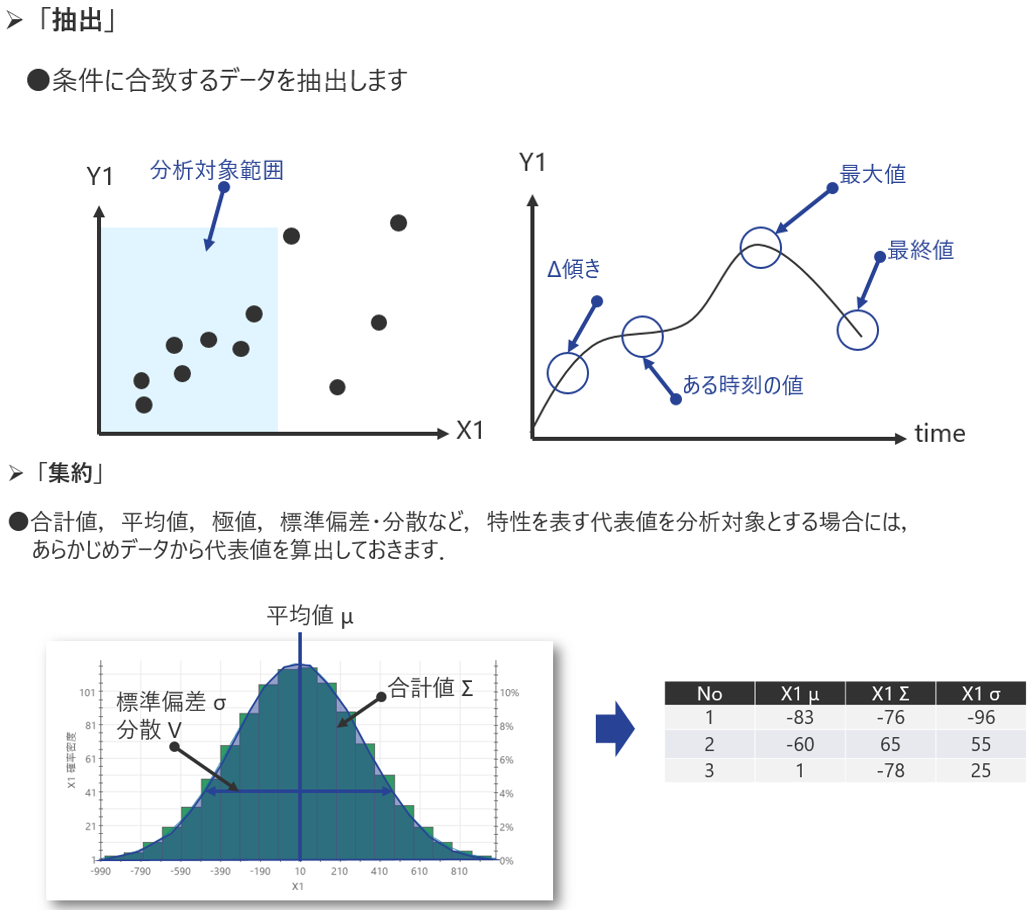
データ構造の加工例
(2)データ内容の加工
データ分析結果の特徴をより明確に捉えられるよう、データそのものを対象に以下のような加工を施します。
-
- 数値データへの変換:カテゴリデータなどの数値データではないデータを数値データに置き換えます。
- 正規化、無次元化:パラメータ(列データ)間を相互比較する分析の場合には、スケールをあわせるためにデータを正規化したうえで分析します。
- 外れ値の除去:極端に大きな値や小さな値が存在するとその値の影響を受け、データ分析結果が大きく変わってしまいます。何かしらのルールに基づいて外れ値を除外します。
- 欠損値の補完:欠損値がある場合、予測モデルや平均値、中央値、最頻値などの集計値によって補完します。
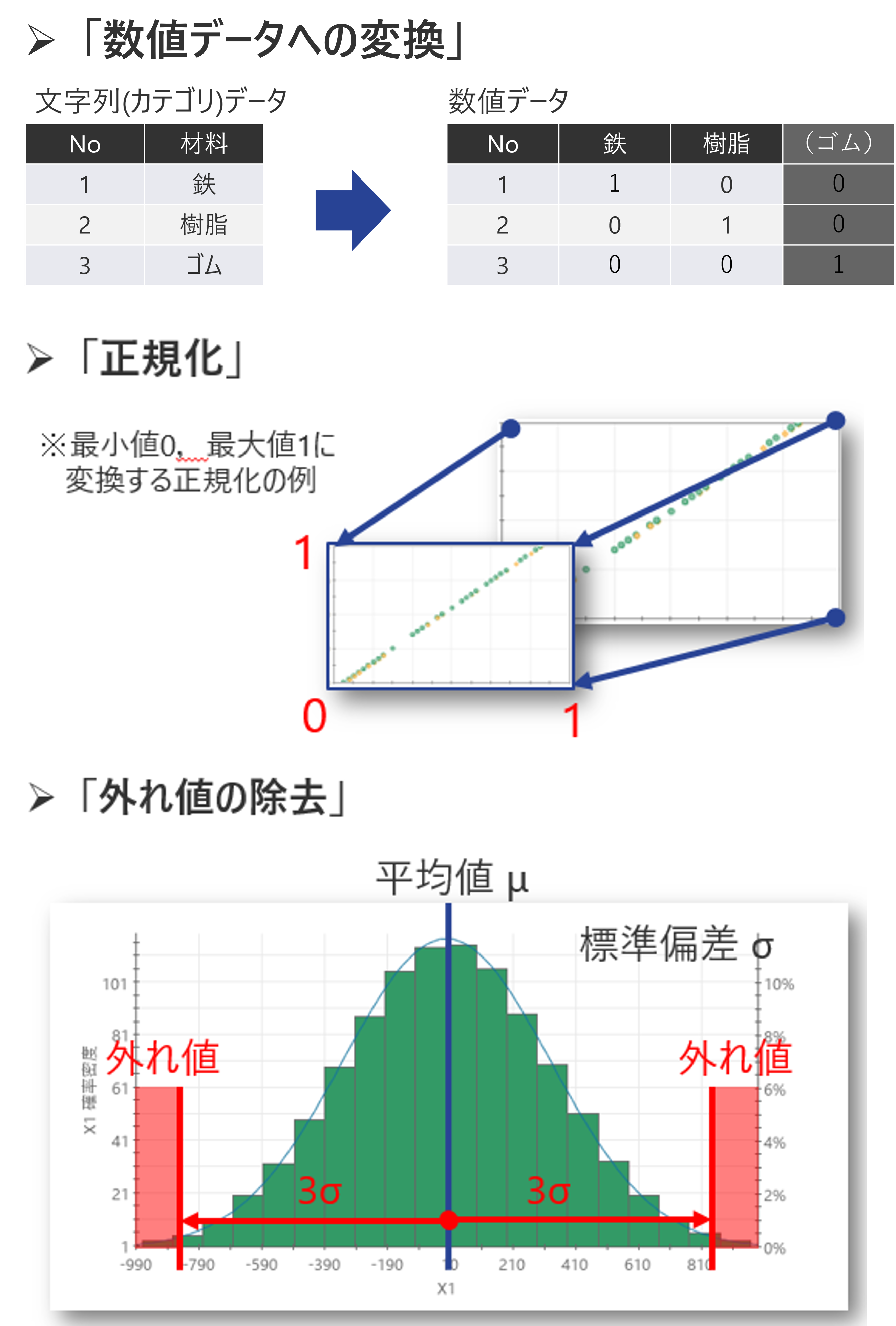
データ内容の加工例
4.データ分析
データ分析では、前処理を行ったデータを使ってデータから知見や洞察などの価値を引き出します。基本統計量や検定など統計分析、相関分析、クラスタリング分析などの多変量解析、機械学習を用いて分析します。
5.データ予測
データ予測では既存のデータから未知のデータを予測するモデルを構築します。予測モデルはモデルを構成する関数によって様々な手法が存在しますが、あくまで入力値と出力値の関係を記述した数学モデルです。あらかじめ物理式のひな形を用意してモデルを作成しない限り、作成した予測モデルが物理法則に則っている保証はない点に注意が必要です。実運用においては、様々な手法で複数の予測モデルを作成し、その中から精度の良いモデルや利用目的に適うモデルを選択するといった方法が現実的な使い方だと思います。
また通常はテキストデータのような構造化データを対象に予測モデルを構築しますが、AI(深層学習)の発展によって、画像データや動画データ、音声データなどの非構造化データのインプット、アウトプットも扱えるようになってきました。深層学習については、「AI(深層学習)への拡張」の項でご紹介します。
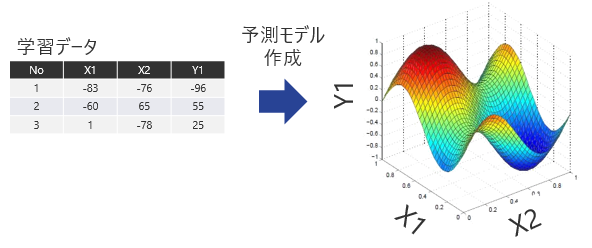
予測モデルの構築例
次回は、modeFRONTIERによるノーコードデータサイエンスについてご説明します。
IDAJがご提案する「RPA(自動化)・最適化・機械学習」ソリューション
設計・開発の舞台が実機からシミュレーションに移ったことで、コンピュータ上での反復作業は増大し、さらに複合的な分野を同時に検討しなければならない設計・開発においては、人の手でだけでは対応しきれないような問題が増加しています。
このような設計・開発環境の変化に適応するため、次のような設計支援ニーズが顕在化しており、それぞれに対する適切なソリューションの選択が、こちらからの設計・開発の成否を分ける可能性があります。
シミュレーションプロセスの構築と、RPA・最適化・データマイニング・機械学習を備えた多目的設計支援ツール
modeFRONTIERページへ
Webベースの設計者展開・データマネージメント・コラボレーションを実現するSPDMツール
無料オンラインセミナー(Webinar)
弊社では、RPA(自動化)・最適化・機械学習、modeFROPNTIERにご興味のあるお客様を対象に、常設で下記のオンラインセミナーを開催しています。
最適化・自動化に取り組まれる方、modeFRONTIERとはどのようなツールか知りたい方、各種ソフトウェアとの連携方法を知りたい方に
はじめよう!使おう!modeFRONTIERセミナー(無料・オンライン)
いよいよ、最適化の実践に取組まれる方に
これで分かる!最適化基礎・多目的ロバスト設計コース(無料・オンライン)
modeFRONTIERをまずはお試しから!
■オンラインでの技術相談、お打合せ、技術サポートなどを承っています。下記までお気軽にお問い合わせください。ご連絡をお待ちしています。
株式会社 IDAJ 営業部
Webからのお問い合わせはこちら
E-mail:info@idaj.co.jp
TEL: 045-683-1990