マツダ 様(IDAJ news vol.119-2)
シミュレーションデータ共有プラットフォームにAras Innovatorをご活用
マツダ株式会社
統合制御システム開発本部 様
IDAJnews vol.119お客様紹介コーナーより抜粋
発行日2025年3月
解析種別:DX、データ管理、PLM、SPDM、MBD、管理用プラットフォーム
課題等:データ管理、データ再利用、業務効率化、統合MBDプラットフォーム、サロゲートモデル、AI、機械学習
省略
シミュレーションデータを正しく蓄積し、再利用することが今後の課題
- 今回のプロジェクトの目的となったシミュレーションのデータ管理が必要になってきた背景についてお聞かせいただけますか。
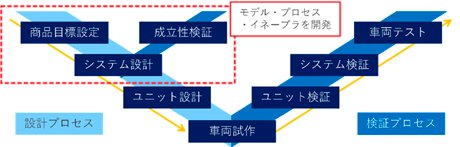
- 現在、主に担当しているのは企画構想段階を対象としたMBDの技術開発です。V字プロセスの左上部の企画段階では、商品目標を設定してシステム設計、ユニット設計を行います。このフェーズにMBDの技術を適用し、上流段階で企画の成立性を検証できるようにしていこうとしています。もちろん企画段階であるため、あまり詳細な情報がなく、構造というものは全く存在しない状態です。したがって、1Dシミュレーションすら難しい状況となりますので、0Dと呼ばれる機能レベルのモデルをパワートレイン、シャシ、ボディといった各領域全体を横断して適用し、最終的にどの程度の機能配分とコストになるかを検討するまでが対象です。
一見すると、データの蓄積や再利用とは関係ない話のように聞こえるかもしれませんが、この技術開発が完了して企画の現場でシミュレーションができるようになった時に、"シミュレーションに必要なデータを集められない"という問題が新たに発生することを見越して、このプロジェクトを立ち上げました。形状のCADデータはしっかり管理されていますので入手するのは簡単ですが、システムの振る舞いに関わる特性データやモデルは、現状では集中管理されているわけではありませんので、データの収集に時間を要します。特に他領域・他分野の情報を集めようとする場合は、そもそもどの部署が情報を持っているのかわからない、問い合わせしても担当者が分からずにたらい回しにされるという問題が発生します。実際に、データを集めるのに右往左往し、それだけで一か月もかかってしまったということも決して少なくありませんし、パワートレイン、シャシ、ボディといった領域を横断するシミュレーションを実施しようとすると問題はより顕著になります。 - 加えてDXの推進やAI技術の進化に伴って、データをいかに正しく蓄積してそれらを再利用するかが、今後の重要な課題になるものと考えています。企画の構想書やシステム設計、CAD・実験データなどはデータベースに登録されていますが、しっかりきちんと管理されているのは各データの最終的な結果データのみで、結論に至るまでのデータやモデル、特性といったデータのほとんどがエンジニアのPCの中に埋もれた状態になっています。企画段階で成立性を検討するには、どうしてもこういった情報が必要です。
そこで"シミュレーションに必要なデータをいかに効率よく回収するか"をテーマに、今回ご紹介する活動を開始しました。
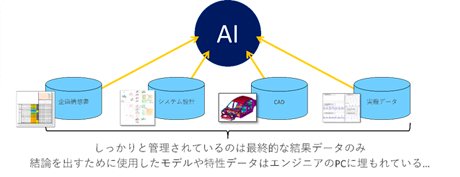
データを登録する側にメリットとなる"魅力機能"を付与したプラットフォーム
- ここからはシミュレーションデータ共有プラットフォーム全体の戦略についてのご説明をお願いします。
- 設計する上で欠かせない、形状や特性などの必要な情報が集まってくるのが"解析業務"です。したがってこの解析業務をターゲットに、各担当者が扱っているデータを収集する仕組みを構築することにしました。
シミュレーションには、大まかに3つの工程があります。まずは、モデルやデータを準備する工程です。モデルやデータは管理されたデータベースから必要なものを取り出しますし、存在しない場合にはデータを作成します。
その後にシミュレーションを実行します。これまでは大規模計算がそう多くはなかったため、個人のPCで計算を実行してきましたが、AI技術などの進展によって大量の計算を行うことが増えていますので、社内のオンプレミスのスパコンや、クラウドといった大規模計算環境を使った計算も増えましたね。
そして最終工程では、計算で得られた大量のデータを人間が理解できるように可視化して分析します。
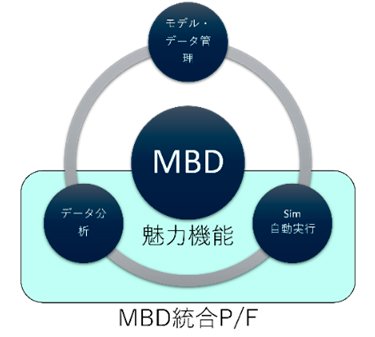
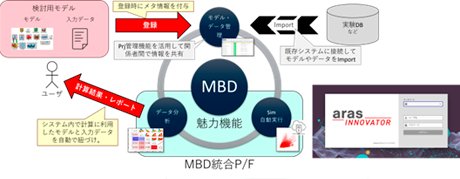
これら各工程の情報をシームレスにつなぐことで、MBDで要求される作業を効率化し、さらにシミュレーション工程の中で、シミュレーション実行とデータ分析(図3 水色枠)の各工程に"魅力機能"を付加して、これを最大化することによってプラットフォームにデータがどんどん入ってくる、そういった流れを持つ、統合MBDプラットフォームを開発しようとしています。 - このプラットフォームがターゲットとするユーザは、自分のPCの中でモデルや各種データを保存しています。プラットフォームに付与されている魅力機能を使うには、モデル・データを管理する場所(図4中央上段)にモデルを登録する必要があるというわけです。もちろん、登録時には検索性を上げるためのメタ情報を付与してもらいます。シミュレーションに必要なデータを準備するには、実験データなども必要になりますので社内の実験データベースと連携してデータのコンバートもサポートしたいと考えています。また大規模計算環境を使って計算し、多種多様なデータを解析する機能から、自動的にレポートを作成してユーザに返すという機能を持たせることも検討しています。
- 続いて、この全体戦略に至るまでの流れをご説明します。
最初に、データが蓄積されたデータベースを、どうやって運用すべきかということを、システム構築後に実現される仕事の流れをイメージしながら検討しました。こういった仕組みの構築でイメージするのは中央集権型のPLMやSPDMのシステムだと思いますが、中央集権型のシステムにしてしまうと、多種多様な解析業務を一般化した上で業務標準を整備する必要が生じるため、どうしても成功するイメージが持てませんでした。一方で、ご経験がある方もいらっしゃるかもしれませんが、共有サーバ型を採用した場合の典型的な失敗である"誰もデータを登録しない"という状況は、想像に難くありませんでした。中央集権型の仕組みなら業務標準として登録を必須化することができますが、共有サーバ型ではデータの登録はユーザの自由意思に委ねられることになります。
これらメリット・デメリットを踏まえて、共有サーバ型の仕組みとする方針に決めたのは、誰もデータを登録しないという状況は、データを登録したくなるような魅力機能を付加することで回避できると考えたからです。今回の場合は、それが大規模計算であり、データ分析の可視化機能であり、サロゲートモデル化であったわけです。
魅力機能を提供するための大規模な商用プラットフォームはありますが、現場で必要とする機能は千差万別ですから、カスタマイズという点で、大規模商用プラットフォームでは融通が利かない可能性があります。ということは、やはり内製化が必要だということで、オープンアーキテクチャを採用しているAras Innovatorをプラットフォームとして採用しました。 - 共有サーバ型を採用した経緯をもう少し詳しくご説明します。
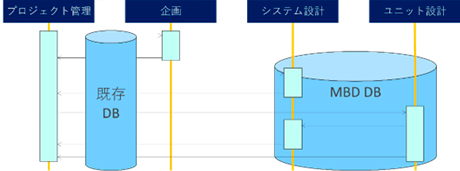
中央集権型のシステムの場合、想定した仕組みが実現できれば、確実に情報を集めることができます。プロジェクト管理者やシステム設計者が、企画担当者やユニット設計者に対して「こんな検討をしてほしい」、「この要件で実現手段を出して欲しい」といったやり取りを、既存のデータベースを経由して実施できるからです。
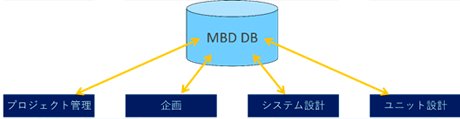
今回、私がターゲットとしているのは、システム設計やユニット設計が関わる領域なので、既存のデータベースとは別に、新しくMBDデータベースを用意すれば良いのではないかと考えましたが、そこには問題がありました。マツダという会社の特徴でもあるのですが、当社はMBDがかなり浸透している会社です。解析専任者もいますが、基本的には設計や実験の現場のエンジニア自らがシミュレーションしています。彼らはすでに、何かしらのモデルやデータの管理ルールを持っています。そういった環境に対して、上意下達に「新しいルールを決めたので従ってください」と言っても、現場でうまくいっている仕事の流れを阻害する、ともすれば改悪となる可能性が考えられました。仮に新しいルールに変更することができたとしても、社内標準の作成、成果物の定義などに途方もない労力がかかる上、最終成果物は回収できても、やはり中間生成物は回収できません。またプロジェクト管理者やシステム設計者も、非常に広範囲な領域をサポートしていますので、中間生成物までカバーする余裕がなく、この中央集権型の管理ではどうやっても無理だなと思いました。 - では、共有サーバ型ではどうか。実現できた場合、ユーザ自らがデータを登録していきますので運用コストはほとんどかかりません。しかし、先ほどお話しした通り、データは果たして登録されるのか、登録されたとしても管理ルールがなければ乱雑に格納されたデータが増えるばかりで、目的のデータを探すのが難しいのではないかという2つの問題があります。ただ、データ検索の問題に対しては、昨今、目覚ましい発展を遂げているAI技術を使えば、何かしらの解決策が見つけられるのではないかなと思います。
となると問題は、どうすれば共有サーバにデータを登録してもらえるのかということです。ユーザに対して「共有サーバを活用してデータを共有し、有効活用しましょう」と呼びかけると、たいていの方は「いいことですね。みんな困りますので協力します」というポジティブな反応が返ってきます。しかし、いざ運用が開始されると誰も登録してくれないんですね。その理由は明白で、"データを登録する人"にメリットがないからです。データを登録した人には、データに関する問い合わせがきますのでそれらに対応しなければなりませんし、データの品質を担保する必要もあります。ユーザが登録しないのもこういったデメリットの方が勝るからに他なりません。
共有サーバ型で運用するには、誰かの役に立つというだけでなく、データを登録する人に対して直接的にメリットとなる魅力機能の利用を目的化するスキームが必要なのではないかと考えました。 - 御社ではすでに多くのデータベースや管理用プラットフォームなどが稼働しており、それらには何らかのプラットフォームが採用されていることと思います。そういった実績があるプラットフォームでなく、今回はなぜAras Innovatorを採用されたのか、その理由をもう少し詳しくお聞かせいただけますか。
- 今回のシステムは、千差万別の機能・要求に対応するために内製化し、小回りが利くようなシステムである必要がありました。そのためのシステム要件としては、データベースの拡張が容易であること、データの履歴管理ができること、アクセス制御やワークフロー定義ができるといった基本機能に加えて、開発した追加機能の拡張プログラムをプラットフォームのシステムイベントの処理に組み込めること、GUIを容易に変更できること、内製化しますので私たち自身でシステムに手を加えることができなければなりません。
一方で内製化と言っても、多くのシミュレーションツールとの連携が必要になるため、すべてを自分たちで対応することは不可能です。そこで、私たちが苦手な領域だけ、部分的に機能実装を請け負ってもらえる協力会社がその分野ごとにいらっしゃることが条件であり、これが選定する上での決定打になりました。
この協力会社の条件が、機能実装という技術を持っている会社というだけであれば選択肢は広がるのだと思いますが、システムを利用するユーザの業務をよく理解して、サポートしていただける会社でなければ、スピード感をもってシステム構築を進めることは難しいと思っています。これらを踏まえて、オープンアーキテクチャが採用されているAras Innovatorと、それを提供されているIDAJさんのご提案を選択することにしました。
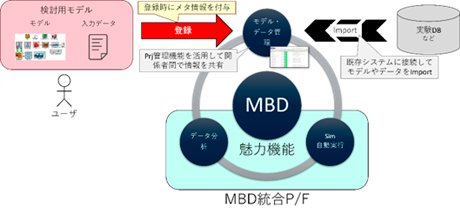
エンジニアの作業を代行する"MBDアシスタント"を目指して
- Aras Innovatorはご認識の通り、オープンアーキテクチャを採用しているため、お客様ご自身で業務に合わせたシステム開発を行うことができ、それをローコードで実現できるところが特徴です。またIDAJには、シミュレーションツールのユーザとしての豊富な経験と知識、そしてITにも精通したエンジニアが在籍していますので、今回のようなシステム構築に対するご支援は、得意領域の一つでもあります。まだ完成にはいたっていませんが、GT-SUITEモデルのサーバ実行機能の実装をIDAJで対応させていただいています。こちらについて、簡単にご紹介いただけますか。
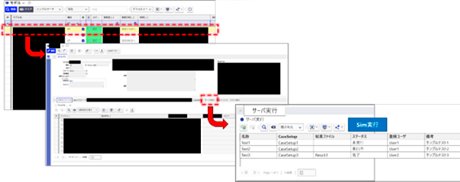
- 画面イメージを示しながらご説明します。実データが表示される部分は黒塗りでマスキングさせていただきました。ご容赦ください。
まず、GT-SUITEモデルは、ユーザの多くがなじみのあるデータベースで登録します。登録したモデルを開くと、モデルの情報や登録されているファイル群、モデルのサムネイルを表示する機能が実装されています。サムネイルは必要ないだろうという気がしますが、ユーザがシステムを利用するか否かを判断する最初の障害として"見た目の印象"というものがありますので、見栄えをよくするということも重要だと考えて取り入れました。
画面をよくご覧いただくと、モデル検索用の情報が明らかに少ないと感じられるかと思います。これはターゲットとしている分野があまりにも広いので、共通のタグで定義しきれないためです。代わりに、いわゆるハッシュタグのようにユーザが自由に、好きなだけ検索情報を追加できる機能を実装しました。
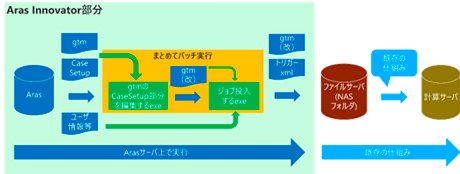
登録したGT-SUITEモデルの計算条件などは、ケースセットアップで定義していますが、このケースセットアップをAras Innovator上で編集をし、それを計算サーバに投入するという仕組みになっています。 - 図9の緑エリアがAras Innovatorで実行している部分です。計算サーバは、社内で利用しているオンプレミスのスパコンを流用しています。この計算サーバには、ジョブを投入するためのファイルサーバがあり、それを常時モニターしていますので、ファイルが投入されたことを検知して計算サーバに投入する仕組みになっています。つまりユーザは、ファイルサーバに計算に必要な情報だけをポンと放り込めば良いというわけです。
Aras Innovatorでは登録されているモデルのファイル、GT-SUITEの場合はgtmファイルを抽出し、Aras Innovator上で定義した計算条件をモデルの中に上書きして計算用の新しいファイルを生成します。この生成したファイルをファイルサーバに投入する処理を追加することで、ファイルが自動で投入される機能を実装しました。
これはAras Innovatorの拡張性のおかげなのですが、Aras InnovatorではユーザのPCで行う処理とサーバで行う処理をそれぞれ定義することができます。誤解を恐れずに申し上げると、イベントでキックするプログラムさえ作ってしまえば、何でも実装することができるという状態になっていますので、その時々の要求に沿った機能実装を比較的簡単に実現することができます。 - 今、ご紹介したサーバ実行機能は、実はまだユーザに公開していません。なぜなら、この機能はユーザにとってはそれほど魅力的なものではないと考えているからです。すでにスパコンに計算投入するための環境があるわけですから、それを使えば良いということになります。
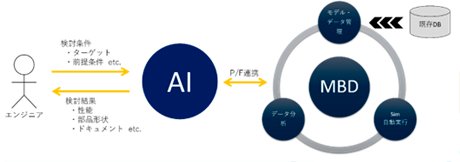
本命は、サロゲートモデルを自動生成する機能です。サロゲートモデルをすでにお使いの方であればおわかりかと思いますが、一度サロゲートモデルを作成すると、どの情報を元に作成したのかということが情報として残りません。仮に、エンジニアが自分のPCで計算してサロゲートモデルを作成したとすると、後で何かあったとしても、計算に使用した条件やモデルファイルが作成者であるエンジニア個人のPCの中にあるため、確認のしようがありません。この問題は、サロゲートモデルの作成者本人が認識していることなので、この新しい環境で作成さえすれば簡単にトレースができるということは、魅力機能の一つとしてユーザに訴求できるのではないかと思っています。
また、社内の他のデータベースとの連携、異なるツールで作成されたモデルのモデル間変換、大規模最適化問題への対応、そしてAIアシスタントといったものも実装したいと考えています。
これらが実現できれば、エンジニアが行っているシミュレーションに関する作業を代行する"MBDアシスタント"機能の実現も可能になってくるのかなと思います。まだまだ着手できてない夢物語ではありますが、エンジニアがAIに対して、性能目標や大きさ、条件を示して計算実行を指示すれば、AIがサーバ実行のプログラムを自分で書いて、計算を実行することをイメージしています。これらすべてをAIでカバーするのはなかなか難しいところがありますが、このMBDプラットフォームの機能をAIがキックして結果を吸い上げ、ユーザがわかりやすいような形にデータを加工してユーザに返すというようなことは実現できるのではないかなと考えています。
正直なところ、このシステムを構築しようとした当初は、ここまでの構想は思いついていませんでした。いろいろと考え、試行錯誤するうちに「あれ?ここまで作れるんじゃないか?」と気づかされましたので、チャレンジングではありますが、これらを目標に活動を継続していくつもりです。
管理ではなく業務の効率化が目的。既存システムを補強し、モデルの氾濫を抑制。
- 詳しくご説明くださいまして、どうもありがとうございます。中央集権的ではない管理方法というコンセプトは、やはり、これまでの様々なご経験を踏まえての結果でしょうか。
- 社内にはDXの一環として様々なデータ管理が検討・運用されていますので、このシステムの目的は、管理ではなく、既存のシステムを補強して業務を効率化する点にあります。そもそもシミュレーション業務での中間生成物を作成する過程の作業、またその中間生成物を管理するとなると、ユーザの立場では非常にハードルが高くなることを実感していました。私自身の目的を達成するには、ルール化して、企画のためのデータさえ集まればそれで良しとも言えますが、それだけではなく、魅力機能を実装することで、データを集めること以外のユーザ側のニーズに応えることができればと考えました。"気軽に登録できるんだけど、しっかり残る"という、ユーザに負担の少ないスキームを目指しています。
- 確かにそうですね。ファイルサーバ的な管理では、データが属人化する懸念もありますし・・・。
- はい、ファイルが勝手に消える、フォルダが分割されるなどデータを担保できなくなりますからね。一昔前のシミュレーション業務における関心ごとは、シミュレーションできる領域や分野、計算精度の向上ではなかったかと思います。もちろん現在でもそれらに対する取り組みは継続していますが、多くのシミュレーションが現場で使えるレベルになった今、どんな課題があるかというと"モデルの氾濫"です。社内には無数の派生モデルが存在し、同じ部署であっても担当者が違えば、異なるモデルを使っているという状況が、そこかしこで発生しています。私にも、モデルを適切に管理したいというリクエストが入っています。今回ご紹介したシステムでは、今のところ、登録管理の機能がメインではありますが、それに魅力を感じて登録したいという人も多いです。
MBDの浸透によって、モデルとモデルをつなぎ、より大規模な検討ができるようにするという時代に入っていますので、"モデルの生い立ち"と言えるような情報を残せないというのは、非常に具合の悪いことになりますね。一方で、モデルの素性を明らかにすることに注力しすぎると、ルールでがんじがらめのシステムとなり使い勝手は悪化します。それでは魅力が目減りしますので、バランスの取れた仕組みにする必要があると思っています。 - このシステム構築のプロジェクトは、着想からどれくらいの期間で立ち上げられたのでしょうか。
- 構想期間としては半年程度でしょうか。その後、無償で利用できるAras InnovatorのCommunity版を利用して、1年をかけて評価や概念実証作業を進め、2023年からサブスクリプション版を契約し、本格的に導入しました。データベースを準備しているころに、IDAJさんからAras Innovatorの紹介を受けましたので、導入にはちょうど良いタイミングでした。
省略
このインタビューの詳細は季刊情報誌IDAJ news vol.119でご覧いただけます。
ユーザー登録済の方はユーザーサポートセンターからダウンロードできます。
ご活用いただいている製品
- 分野1:
- 熱流体解析
- 分野2:
- 1Dシミュレーション(システム・シミュレーション)、システム開発(解析システムを含む)

