Ansys EnSight汎用ポストプロセッサー
特徴
大規模データへの対応
数値解析は、ますます大規模化し、それにより取り扱うデータ量が増大しています。Ansys EnSightには、大量のデータを効率よく処理する様々な機能が搭載されています。
必要最小限の使用メモリー
Ansys EnSightは、可視化に必要になったときにはじめて、それに必要なデータ成分(変数)を追加で読み込みます。また、不要になったデータ成分は、いつでもメモリーから解放できます。
完全64ビット対応
64ビットOSのマシンでは、2GB以上のデータを取り扱うことができます。
ポリゴン・リダクション機能
形状やコンターの色の分布をできる限り保持したまま、画面に表示するポリゴン数を自動的に削減します。これにより、レンダリング(描画処理)の負荷を下げ、高速表示を実現しています。
クライアント/サーバー機能
可視化に必要な計算処理とレンダリング処理を、サーバーとクライアントで負荷分散する機能です。また、サーバーにあるデータ・ファイルをクライントのPCに転送する必要がないため、データを一元管理することができます。
マルチスレッドによる並列化
マルチスレッド並列処理によって処理時間を短縮します。Ansys EnSightでは最大8並列まで、Ansys EnSight Enterpriseでは最大128並列の処理が可能です。
クラスターシステムでの分散処理
可視化処理をクラスターシステムで分散化することができます。(Ansys EnSight Enterprise)
バッチ処理による大量データへの対応
流体と構造の連成解析結果を可視化
異なるデータに対し、個別に可視化して重ね合わせて表示することができます。異なるデータに対し、時間ステップを合わせてアニメーション表示することができます。
ボリュームレンダリング
視線上にある表示物性値の積算値を合計(レイキャスティング)して異なる透明度で表示することで、3次元空間の分布を表現する手法です。Ansys EnSightでは、高速かつ高品質に表現します。大規模データに対しては、構造格子にサンプリングすることも可能です。
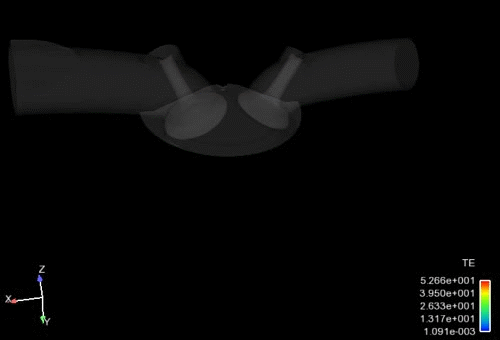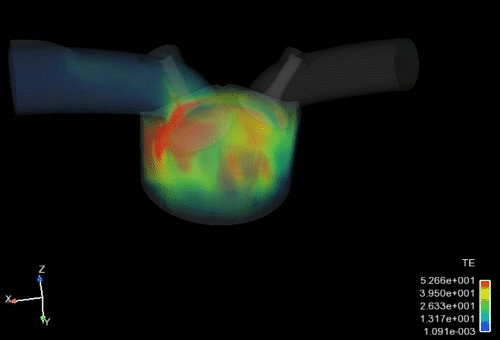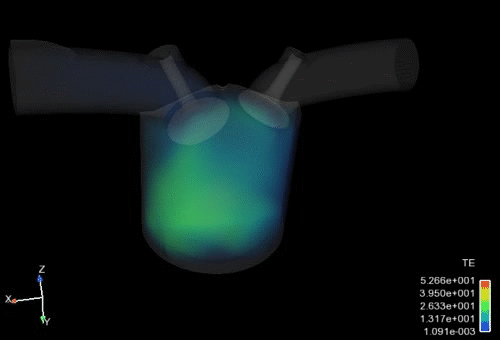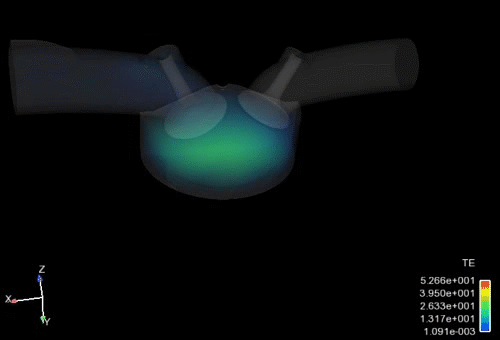

Caseリンキング機能
複数の似通った結果を効率的に比較表示することのできる機能です。一つ目の結果処理に追加読込みすると、自動的に同じ結果処理が追加したデータに対して適用されます。その後の断面作成や位置の移動、グラフ作成などのすべての操作は、読み込んでいる複数のデータ全てに適用され、連動した視点で表示されます。
より効率的な作業環境
PythonスクリプトでAnsys EnSightのコマンドを制御することが可能です。PyQtを使って独自のGUIを作ることもできます。たとえば、いつも行う一連の操作を、独自のボタン1つで実行させることが可能になります。

